https://github.com/cornell-zhang/bnn-fpga
http://dx.doi.org/10.1145/3020078.3021741
1.Introduction
- Studying FPGA acceleration for very low precision CNN;
- Ensuring full throughput and hardware utilization across the different input feature sizes;
- Implement BNN classifier on Zedboard;
2.Preliminaries
- Comparison of CNNs and BNNs
- Introduction of Convolutional, Pool, and FC;
- Introduction of Binarized Neural Networks(BNN);
y = \frac{x-\mu}{\sqrt{\sigma ^{2} + \epsilon}}\gamma + \beta
-
CIRAR-10 BNN Model;
★ 3.FPGA Accelerator Design
3.1 Hardware Optimized BNN Model
- Removing the biases of this model;
-
Involving the batch norm calculation as y = kx + h :
k = \frac{\gamma}{\sqrt{\sigma ^{2} + \epsilon}}
h = \beta - \frac{\mu \sigma}{\sqrt{\sigma ^{2} + \epsilon}}
This reduces the number of operations and cuts the number of stored parameters to two.
- Empirical testing shows that k and h can be quantized to 16-bit; Quantizing the floating-point BNN inputs to 20-bit;
3.2 Retraining for +1 Edge-Padding
- Using the 0 padded BNN rather than -1 or 1;
3.3 System Architecture
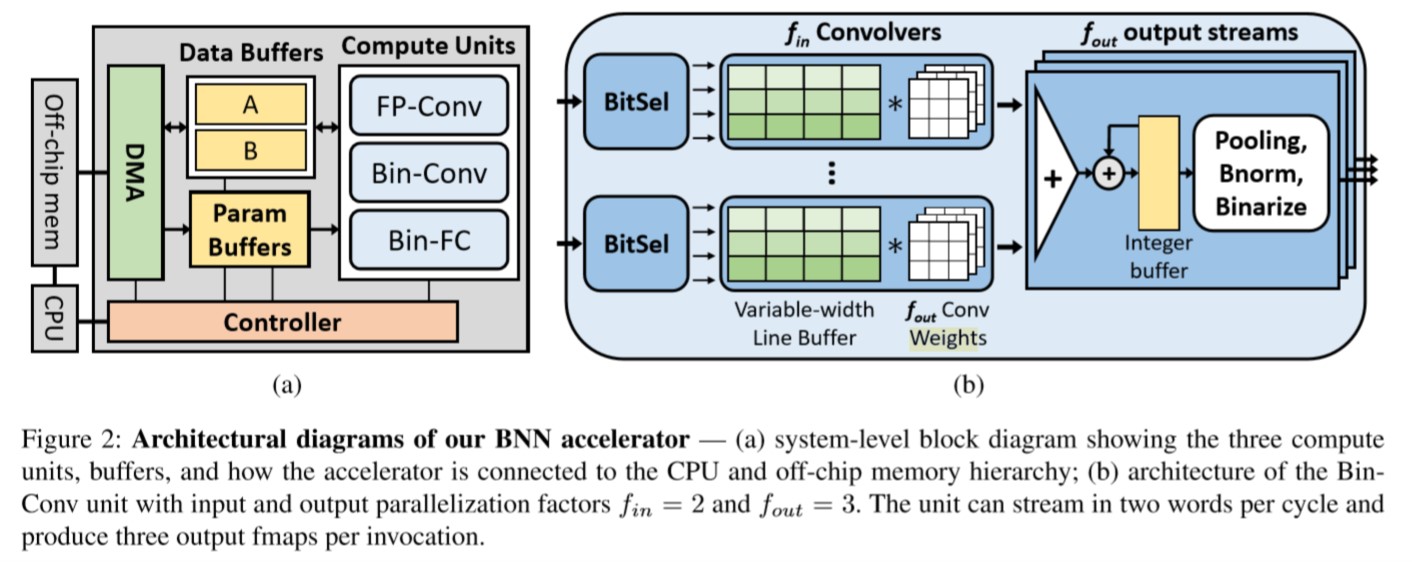
- Ping-Pong Buffer A and B
3.4 Compute Unit Architectures
FP-Conv
- Utilizing the line buffer architecture for 2D Conv;
- Replacing the multiplies in the Conv operation with sign inversions;
- Parallelizing across the three input channels(one output bit per cycle);
Bin-Conv
- Designing targets 8, 16, or 32, and supporting port larger power-of-two widths with minor changes.
- A standard line buffer is unsuitable for this task:
a. A line buffer must be sized for the largest input fmap(width of 32)
b. A line buffer is designed to shift one pixel per cycle to store the most recent rows. - BitSel & variable-width line buffer(VWLB)
a. The BitSel is responsible for reordering the input bits so that Convolver logic can be agnostic of the fmap width.
b. Each Convolver applies f_{out} 3x3 Conv filter per cycle to data in the VWLB.
c. For 32-wide input, each word contains exactly one line. Each cycle, the VWLB shifts up and the new 32bit line is written to the bottom row. They Slide the 3x3 conv windows across the VWLB to generate one 32-bit line of conv outputs.
d. For an 8-wide input, each word contains four lines. They split each VWLB row into four banks, and map each input line to one or more VWLB banks.
Advantages:
- The VWLB achieves full hardware utilization regradless of input width;
- A new input word can be buffered every cycle;
- The BitSel deals with various input widths.
4. HLS Accelerator Implementation

- In BNN accelerator, the basic atom of processing is not a pixel but a word.(word per cycle)
- To increase the number of input streams they tile the loop and unroll the inner loop body.
- 64 convolutions per cycle
- Data buffer A and B at 2048 words

